 手机浏览网
手机浏览网


关键词:售电量;多模型融合;预测
0、引言
随着我国电力行业的快速发展,电力系统中对售电量预测的要求越来越高。 正确预测出地区销售电量的水平,为电力企业提供营销决策支持,对于指导发电厂、输配电网的合理运行,推动电力市场的发展和建设都具有十分重要的意义。
常用的预测方法很多,基本上分为传统预测法与智能预测法两类。传统预测方法主要有经验法、回归分析法[1]、灰色预测法[2]、时间序列法[3]、指数平滑法等。智能预测方法主要包括有小波分析预测法、混沌预测法、模糊理论预测法、人工神经网络预测法、支持向量机预测法[4]等。但是单一方法的应用都有其局限性,传统预测方法对不同类型的售电量预测没有统一而合理的处理方法,在气候条件、节假日等影响下稳定性较差;智能预测算法由于影响售电量变化的众多随机因素很难用数学模型描述,也给预测的准确性带来了一定困难。因此,采用多种数学方法融合技术,充分运用不同算法各种的优势,取长补短,融合形成精确的、稳定的售电量预测系统。
多模型融合预测方法是一种对多种单一预测模型进行加权求和预测的方法。就一种预测方法而言,在不同的条件下、不同类型的售电量预测精度高低不一。对多种预测方法来讲,在相同的条件和同类型的售电量预测中,各模型的预测结果有很大差异。综合考虑各种基本预测方法在不同条件下预测结果的精度,并将这些信息融合在一起,既可以提高售电量预测结果的精度,又可以保证预测误差的稳定性。本文提出采用Logistics回归分析、ARIMA模型和支持向量机回归模型作为基本预测方法进行融合,研究对月售电量的预测。
1、多模型融合的售电量预测方法
月售电量受经济发展、产业结构变化、季节变化等因素的影响,使其呈现出明显的趋势性、季节周期性以及随机性。
月售电量是具有趋势性、季节性和随机性的非平稳负荷,直接预测难度较大,并且针对应用单一预测模型的预测精度和稳定性不高的问题,运用数据融合技术建立一种多模型融合预测方法。
1.1、ARIMA模型预测方法
ARIMA模型是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型[5]。包括移动平均过程(MA)、自回归过程(AR)、自回归移动平均过程(ARMA)以及ARIMA过程[6]。
结合ARIMA模型定义,可得月售电量序列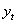 的ARIMA(p,d,q)模型为:
的ARIMA(p,d,q)模型为:
的ARIMA(p,d,q)模型为: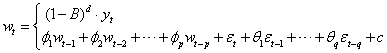
式中: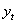 为月售电量序列;d为差分次数;B为滞后算子;
为月售电量序列;d为差分次数;B为滞后算子;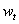 为月售电量序列经过d次差分后形成的平稳序列;
为月售电量序列经过d次差分后形成的平稳序列;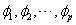 为自回归系数,p为自回归阶数;
为自回归系数,p为自回归阶数;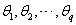 为移动平均系数,q为移动平均阶数;
为移动平均系数,q为移动平均阶数;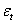 为均值为0,方差为
为均值为0,方差为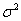
为月售电量序列;d为差分次数;B为滞后算子;为月售电量序列经过d次差分后形成的平稳序列;为自回归系数,p为自回归阶数;为移动平均系数,q为移动平均阶数;为均值为0,方差为的白噪声序列;c为常数;
对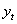 建立ARIMA模型及预测步骤如下所示:
建立ARIMA模型及预测步骤如下所示:
建立ARIMA模型及预测步骤如下所示: Step1:平稳性检验。用ADF检验法对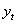 的
的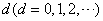 阶差分序列依次进行平稳性检验,直到序列平稳,确定此时对应的差分次数d。一般情况
阶差分序列依次进行平稳性检验,直到序列平稳,确定此时对应的差分次数d。一般情况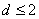 。
。
的阶差分序列依次进行平稳性检验,直到序列平稳,确定此时对应的差分次数d。一般情况。 Step2:模型定阶(确定阶数p和q)。以自相关系数和偏自相关系数为基础,根据这两个统计量的截尾与拖尾性质[7]确定ARIMA模型阶数p和q,其确定方法为下表1-1所示。
表1-1 模型定阶方法

Step3:参数估计。用最小二乘法估计模型(2)中除了P、d、q以外的其他参数:c、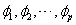 和
和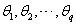 。
。
和。 Step4:模型检验。检验所建模型的残差序列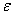 是否为白噪声序列。这一过程仍以自相关系数和偏自相关系数为基础。若在
是否为白噪声序列。这一过程仍以自相关系数和偏自相关系数为基础。若在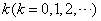 期滞后的自相关和偏自相关系数均趋于0,表明该残差序列为白噪声序列,转步骤5;否则,为非白噪声序列,返回步骤2重新构建模型。
期滞后的自相关和偏自相关系数均趋于0,表明该残差序列为白噪声序列,转步骤5;否则,为非白噪声序列,返回步骤2重新构建模型。
是否为白噪声序列。这一过程仍以自相关系数和偏自相关系数为基础。若在期滞后的自相关和偏自相关系数均趋于0,表明该残差序列为白噪声序列,转步骤5;否则,为非白噪声序列,返回步骤2重新构建模型。 Step5:预测。得到合适模型后,应用模型(2)预测月售电量。
1.2、支持向量机回归模型预测方法
支持向量机回归(Support Vector Regression,SVR)算法是基于Mercer核展开定理,是支持向量机用于回归中的情况。支持向量机的基本原理是寻找一个既能将样本无误分开,又能使分类间隔(Margin)最大的最优分类线,如图1-1中H所示。对于样本非线性可分的情况,可先通过非线性变换将输入变量x映射到一个高维空间(Hilbert空间)中,在高维空间中进行分类运算,得到最优分类面,从而将样本无错误分开。支持向量机根据有限的样本信息在模型的复杂性和学习能力之间寻找最佳折衷,使得结构风险最小化,以获得最好的学习泛化能力。因此,该方法能够较好地解决小样本、非线性、高维数问题,常被用于识别[8]和预测[9]。

图1-1 最优分类面示意图
通过构造损失函数,并基于结构风险最小化思想,支持向量机通常采用以下极小化优化模型来确定回归函数[10],即:
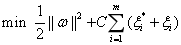 (1)
(1)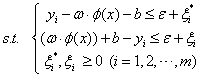 (2)
(2) 式中: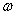 为权值向量;
为权值向量;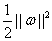 为模型复杂性的表达项;C为平衡系数;
为模型复杂性的表达项;C为平衡系数;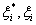 为松弛因子;
为松弛因子;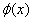 是将数据映射到高维空间的非线性变换;
是将数据映射到高维空间的非线性变换;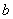 为偏置;
为偏置;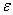 为误差上限。
为误差上限。
为权值向量;为模型复杂性的表达项;C为平衡系数;为松弛因子;是将数据映射到高维空间的非线性变换;为偏置;为误差上限。 引入Lagrange乘子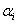 和
和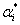 ,式(1)与式(2)所示的优化模型可转化为以下对偶优化问题求解:
,式(1)与式(2)所示的优化模型可转化为以下对偶优化问题求解:
和,式(1)与式(2)所示的优化模型可转化为以下对偶优化问题求解: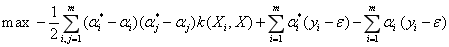
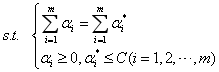
求解上述问题可得到支持向量机回归函数:
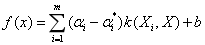
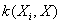 称为核函数,需满足Mercer条件,选取高斯RBF核函数[11],为:
称为核函数,需满足Mercer条件,选取高斯RBF核函数[11],为: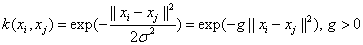
在支持向量机计算过程中涉及到两个参数,即:权重系数C和核函数参数g。本文采用网格搜索法进行优化[12]。
1.3、多模型融合预测方法
1.3.1、融合模型的建立
电力企业售电量受经济发展、产业结构变化、季节变化等因素的影响,使其呈现出明显的趋势性、季节周期性以及随机性,因此,对月售电量的预测,单独使用某种预测方法直接预测难度较大,很难得到比较理想的结果。所以综合考虑各种预测模型的预测结果,以不同预测模型的输出结果为信息源,以提高预测精度为目的,运用数据融合技术对月售电量预测方法进行研究[13]。
对月售电量进行预测时,若能依据在前几个时段内各种预测方法的预测效果,实时调整融合预测模型中各种预测方法的权重系数,就能够改善预测结果的精度和稳定性。前几个时段内,预测误差较小的预测方法在下一个时段内的融合预测模型中所占的权重就大;反之,在下一时段内的融合预测模型中所占的权重就小。这种融合预测模型不仅可以提高交通流参数预测的精度,还可以保证预测的稳定性。多模型融合预测算法计算流程如图1-2所示。
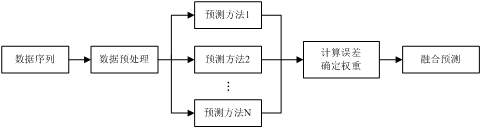
图1-2 多模型融合预测算法计算流程
多模型融合预测方法的预测过程主要有如下几个步骤:
Step1:预测方法的选择:根据预测方法的预测效果以及适用条件等,选择n种被广泛使用的比较成熟的预测方法作为融合预测方法的基本方法。本文将选用时间序列和支持向量机回归作为融合预测方法的基本方法。
Step2:基础预测方法进行预测:利用步骤Step1中选择的每一种预测方法对需要预测的月售电量分别进行单独预测。预测后将会得到n个预测方法的预测值,即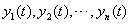 。
。
。 Step3:确定融合预测方法中各基本预测方法的权重系数: 各种基本预测方法在融合预测方法中的权重大小(即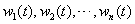 )是根据各种基本预测方法在前几个时段内的预测精度来确定的。权重确定的原则是精度越高,权重越大。
)是根据各种基本预测方法在前几个时段内的预测精度来确定的。权重确定的原则是精度越高,权重越大。
)是根据各种基本预测方法在前几个时段内的预测精度来确定的。权重确定的原则是精度越高,权重越大。 Step4:多个基本预测结果融合:在t时段,将各种基本预测方法的预测结果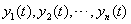 依据权重系数
依据权重系数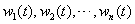 进行加权融合,就可以得到融合预测方法的预测结果
进行加权融合,就可以得到融合预测方法的预测结果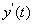 ,计算公式为:
,计算公式为:
依据权重系数进行加权融合,就可以得到融合预测方法的预测结果,计算公式为: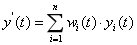
1.3.2、权重系数的确定
在融合预测方法中,某一基本预测方法的权重系数决定了该方法输出的预测值对最终预测结果所起的作用。事实上,随着季节和天气温度的变化,每一种基本预测方法的预测精度均会发生不断的变化,所以融合预测方法中各个基本预测方法的权重系数也应该进行不断调整,为此引入动态误差的概念。
动态误差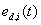 定义为:
定义为:
定义为: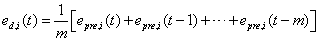
式中: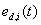 是i方法在t时段的动态误差,它是t之前m个时段内i方法的误差
是i方法在t时段的动态误差,它是t之前m个时段内i方法的误差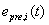 的均值;m是误差累计数;
的均值;m是误差累计数;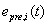
是i方法在t时段的动态误差,它是t之前m个时段内i方法的误差的均值;m是误差累计数;是t时段i方法预测结果的绝对相对误差。
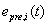 的计算公式为:
的计算公式为: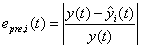
式中: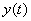 为t时刻的实测数据;
为t时刻的实测数据;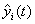 为i方法在t时刻的预测值。
为i方法在t时刻的预测值。
为t时刻的实测数据;为i方法在t时刻的预测值。 权重系数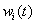 与动态误差
与动态误差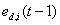 成反比例变化,即动态误差较大的预测方法给予一个较小的权重系数,动态误差较小的预测方法给予一个较大的权重系数。首先,我们通过反比例法得到初始权重系数
成反比例变化,即动态误差较大的预测方法给予一个较小的权重系数,动态误差较小的预测方法给予一个较大的权重系数。首先,我们通过反比例法得到初始权重系数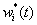 ,计算公式为:
,计算公式为:
与动态误差成反比例变化,即动态误差较大的预测方法给予一个较小的权重系数,动态误差较小的预测方法给予一个较大的权重系数。首先,我们通过反比例法得到初始权重系数,计算公式为: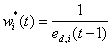
各基本预测模型在融合预测模型中的最终权重系数为:
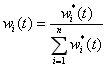
2、实例分析
2.1、案例数据描述
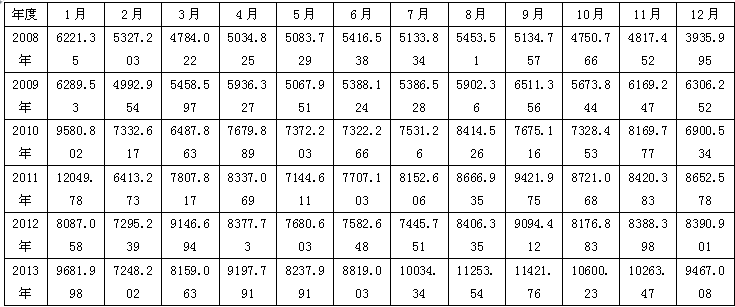
为了检验多模型融合预测模型的可行性,选取A市2008年1月至2012年12月共60个月度售电量数据作为模型的原始数据,并用2013年1—12月的数据作为验证数据,然后将预测结果和实际值进行比较,求出误差评价指标进而验证模型的有效性。A市是我国的经济发达城市,根据该市电力财务报表数据如下表2-1所示。
表2-1 A市月度售电量统计表(2008年-2013年)(单位: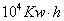 )
)
)
根据表2-1提供的售电量数据,绘制出2008年1月至2012年12月共60个月的售电量折线图(如图2-1所示),该序列是一个剧烈波动的序列,有很明显的增长趋势和季节性,是一个非平稳的随机过程。
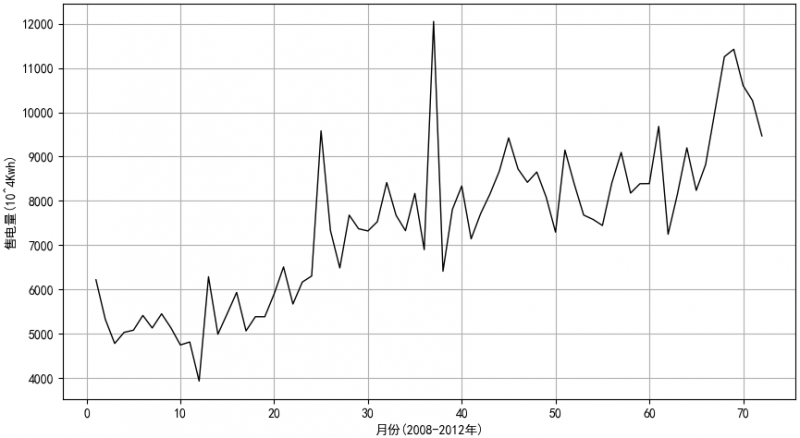
图2-1 售电量时序图
2.2、售电量预测及结果分析
A市2008年1月至2012年12月共60个月度售电量数据作为训练时间序列数据,2013年1—12月的数据作为测试时间序列数据。首先直接使用Logistics回归预测方法经过训练后,预测2013年1—12月售电量;其次,运用ARIMA预测方法通过训练后,预测2013年1—12月售电量;再运用支持向量回归预测方法经过训练后,预测2013年1—12月的售电量;最后,运用本文提出的多模型融合预测方法对2013年1—12月售电量进行预测,在本案例中,多模型融合选择Logistics回归预测方法、ARIMA预测方法和支持向量机预测方法作为基本预测方法。图2-2为上述四种预测方法的预测结果与实际售电量对比图。
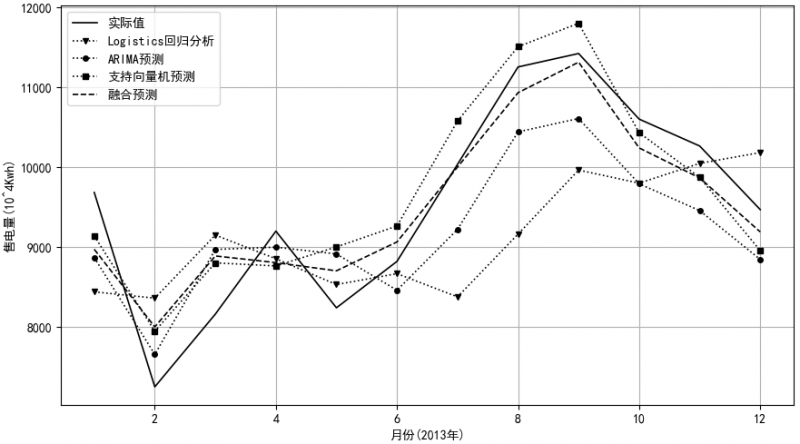
图2-2 四种预测方法的预测结果与实际售电量对比图
为比较上述四种方法的预测效果,引入最大绝对误差(MaxE)、平均绝对相对误差(MARE)和最大绝对误差(MaxARE),其计算公式如下:
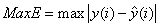
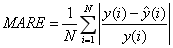
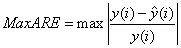
上式中,N是预测数据的个数,本案例中N为12;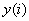 是第i月的售电量实际值;
是第i月的售电量实际值;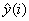 是第i月售电量预测值。
是第i月售电量预测值。
是第i月的售电量实际值;是第i月售电量预测值。 使用MaxE、MARE和MaxARE对Logistics回归预测方法的预测结果、ARIMA预测方法的预测结果、支持向量机预测方法的预测结果和多模型融合预测方法的预测结果进行评价,各预测方法预测误差指标对比如下表2-2所示。
表2-2 各预测方法预测误差对比
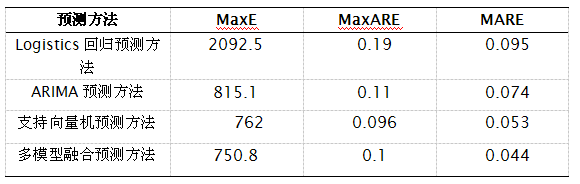
通过月售电量预测值和实际值的对比分析,本文所提出的多模型融合预测方法预测效果优于Logistics回归预测方法、ARIMA预测方法和支持向量机预测方法。因此,运用多模型融合预测方法进行售电量预测能够提高预测精度,保证预测误差的稳定性。
3、结束语
电力系统的售电量受气候,气温和人类活动等因素影响,其变化特征具有随机性和不稳定性。本文提出一种多模型融合预测方法,将Logistics回归预测方法、ARIMA预测方法和支持向量机预测方法通过多模型融合算法,得到其组合权重系数,此方法综合了各种基本预测方法在不同条件下预测结果的精度,并将这些信息融合在一起得到最终售电量预测值。在某市月度售电量数据预测中运用该方法作为案例验证,案例分析结果表明用多模型融合预测方法对售电量进行预测是可行且可靠的,为电力分配及电网改造提供了重要的理论依据。然而,本文针对售电量预测所提出的多模型融合预测方法也具有进一步优化的空间,因为运用多模型融合预测方法是定量的,完全是由数据驱动的,如何在该方法的基础上加一定的定性分析,弥补数据驱动的不足,仍需要进一步研究。





